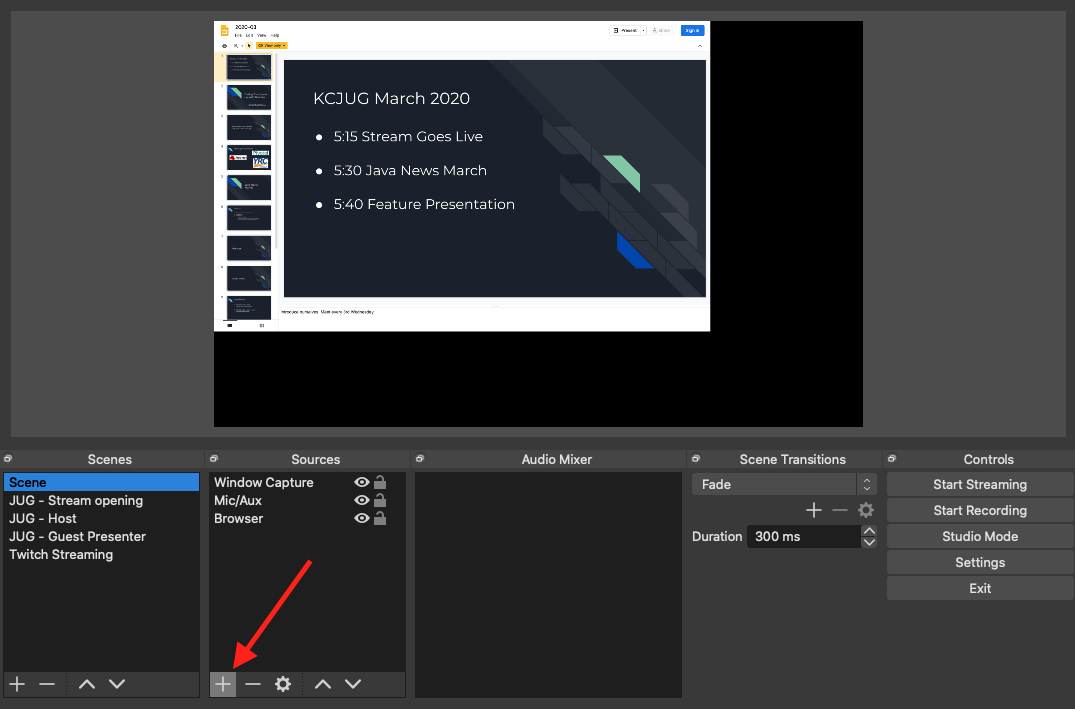
In the previous article on Scripting with Java, we looked at how Java became more approachable as a scripting language using the java launcher to execute single source file Java applications. This allows Java to have the typical ‘write-execute’ development loop that other scripts languages have.
Another trait common among script languages is they have very little formality. To address concerns around the "verbosity of Java" Project Amber was launched in the OpenJDK with the goal of improving developer productivity and experience when writing in Java. In this article we will look at some of the changes introduced to the Java language as a part of Project Amber and how it helps to make Java a more pratical choice to write scripts in.
Code Example
The example we will be using to explore some of the Java language changes is a simple script for scanning text files for a phrase. This script will need to accept user input for; a phrase to search for, the directory to search in, and the file type that will be searched. The script will also need to print formatted messages to the console and display the results of a search. Let’s take a look at how some of the new language changes in Java make these tasks easier to accomplish.
The full code example can be seen here: LogScanner.java
Writing and Formatting Multi-Line Messages with Text Blocks
Printing a multi-line and formatted messages to console is a common need when writing a script. Messages could be needed for providing information on how to use the script, results, or when an error occurs. Working with a multi-line formatted string has often been a painful experience in Java. Introduced in Java 15, JEP 378, Text Blocks aims to address this pain point.
A text block begins and ends with the triple quote delimiter: """. Within the """ formatting and line separations are preserved without requiring escaping or declaration (i.e. \n or \r is not needed to create a new line). Here in the below example, a welcome message is defined:
var welcomeMessage = """
Welcome to log scanner!
Enter the phrase you want to search for and the directory you want to search in.
Author: Billy Korando
""";
System.out.println(welcomeMessage);
Which when printed to the console looks like this:
Welcome to log scanner!
Enter the phrase you want to search for and the directory you want to search in.
Author: Billy Korando
Note that along with the line breaks, even the indentation of Author: Billy Korando is preserved. For more information on how to use Text Blocks including rules around incidental whitespace, be sure to checkout the Programmer’s Guide to Text Blocks.
Declaring Variables with var
In the previous example, you might had noticed that though welcomeMessage is a String, it’s declare with var. This is an example of Local-Variable Type Inference, a feature added in Java 10, (JEP 286. This changed allows local variables, variables declared within the scope of a method body, to be decalred with var instead of a type. Like in this example:
var logStatements = new ArrayList<LogStatement>();
In the above example the actual type is ArrayList<LogStatement>, which is clear enough from the new ArrayList<LogStatement>() on the right side of the assignment operator. Instead of having the declare logStatements as ArrayList<LogStatement> (or more commonly, List<LogStatement>), logStatements can simply be declared with the var and the compiler can infer the type.
While not significant, var can be helpful to reduce some of the cermony when declaring variables in Java when it’s clear what the type should be like in the above example. The addition of var also brings Java into line with many other statically typed languages like C++, C#, Go, and others, which all have a similar type inference capability. For more of recommendations on how to use var, be sure to check out the Local Variable Type Interface: Style Guidelines and the Local Variable Type Interface FAQ.
Creating Data Carriers with Record
Processing data is at the heart of computing, be it in an application or in a script. Often the first step in data processing is defining a data carrier to place data into. Here Java has seen a significant improvement with the introduction of Records, (JEP 395), as a part of Java 16.
Creating a simple data carrier class historically required quite a bit of ceremony in Java; a constructor, accessor(s), and if you were going to check the value of data carriers, implementation of equals() and hashCode(), toString() is also a common need for easy printing of the contents of a data carrier. While IDEs have traditionally supported code generation of these methods, defining a data carrier class within a method was impractical as defining; constructors, accesors, equals(), hashCode(), and toString() often required dozens of lines of code or more. Additionally if changes were made to the fields of a data carrier class, the code generation would have be manually re-run, which if skipped, is an opportunity for bugs to enter a code base.
Records were designed for the concise modeling of data as data in Java. In the example, the record LogStatement collects the file name and full log message that contains the phrase, from the file where the phrased being search for was matched:
record LogStatement(String fileName, String logMessage) {
}
var logStatements = new ArrayList<>();
for (Path p : logFiles) {
String fileContents = Files.readString(p);
Stream.of(fileContents.split("\n")).filter(l -> l.contains(searchTerm))
.forEach(l -> logStatements.add(new LogStatement(p.getFileName().toString(), l)));
}
logStatements.stream().forEach(System.out::println);
While in this example, we are simply using the implementation of toString to print the results, we could, for example, also use the implementation of equals to count how many times to the same line is printed within a file.
Assigning Value with Switch Expressions
Switch Expressions, added in Java 14 (JEP 361), are a great way of more succicntly handling evaluations that have n paths. Here in the example below, a switch expression is being used to set the file extensions of the file(s) to be searched based on user input:
private static String selectFileType() throws IOException {
String fileMessage = """
Select the type of file you'd like to search:
1. .log
2. .txt
3. .md
Your selection: """;
System.out.print(fileMessage);
var fileTypeSelection = new BufferedReader(new InputStreamReader(System.in)).readLine();
return switch (fileTypeSelection) {
case "1" -> ".log";
case "2" -> ".txt";
case "3" -> ".md";
default -> {
System.out.println("Invalid selection");
yield selectFileType();
}
};
}
With switch expressions, only code to the right of the -> is executed, so a break statement is not needed. This behavior also prevents accidental fall through, a common soure of bugs when using a switch statement.
A switch expression can return value as in the example above, which helps to make code more succinct by not requiring an assignment statement (i.e. var x = y;) in every applicable case. Switch expression can also execute code blocks, like in the default case, and a case block will need to end with a yield statement, if the expression is returning a value (or throw an exception).
Switch expressions are required to be exhaustive. In many cases this will often mean defining a default case will be required, but if all paths are covered by a case, as in this example using an enum, a default case is not required.
Conclusion
Project Amber has made considerable progress toward reducing verbosity in Java, helping to make Java a more practical choice for writing scripts in. Project Amber is an ongoing effort and new features in active development include Record Patterns and Array Patterns (JEP 405) and Pattern Matching for Switch (JEP 406), which build upon Records and Switch Expressions respectively. As these changes continue to be added to Java, this should continue making Java a more productive language to write in.
While this article has primarily focused on the language changes that have been introduced to Java in recent releases, there are active efforts ongoing in other areas. A new HTTP Client API was introduced in Java 11 (JEP 321) which support HTTP/2. Convience Factory Methods for Collections, added in Java 9 (JEP 269), allow for easy creation of Lists, Sets, and Maps, with the .of factory method.
One area we haven’t yet touched on is improving startup performance. When running the code examples in this series you might have seen a small, but noticable delay when executing the code with the java launcher. While less, there is still even a small delay when using the java launcher against a compiled class. In the next article, we will take a look at how to improve the startup performance of short running Java applications.
The full code can be found in my GitHub repo here: https://github.com/wkorando/scripting-with-java/tree/article-ii